-
TypeMonkey versus word-by-word subtitles
I use TypeMonkey, the Rolls Royce for creating whizz bang captions, but recently a client wanted *subtitles* animating in the in vogue word-by-word fashion. Whilst TypeMonkey can do this, it’s overkill for the job – needs a lot of setup outside Ae for the marker track and it takes a long time realign each line into the lower subtitle position.
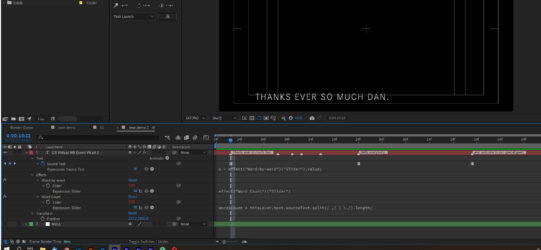
I then explored a different route – I can import the .srt directly into After Effects using a script which produces a single text layer, with all the subtitle text lines keyframed at the corresponding timecode for the start of each line for the entire comp; I also have this Source Text expression by Dan Ebberts which reveals each word in the line depending on a Slider value:
s = effect(“Word-by-word”)(“Slider”).value;
str = “”;
txt = value.split(” “);
for (i = 0; i < Math.min(txt.length,s); i++){
str += (i > 0 ? ” ” : “”) + txt[i];
}
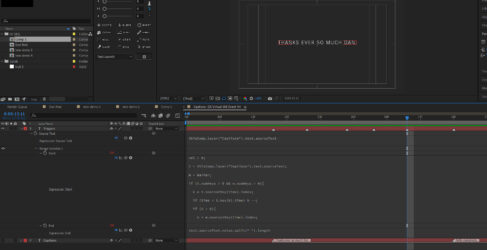
strStage 2: I ran a (Dan Ebberts!) Text to Markers script on the text layer to create (named) markers whenever there’s a Source Text keyframe, which puts a marker at the beginning of every subtitle line on the entire layer; if I play back the timeline along with the source layer audio, I can then use the * key to manually add additional markers for each subsequent word on the text layer.
What I’d like to do is add an expression to Slider Control that firstly looks at the Source Text properties, and returns a value of 1 if there’s a Source Text keyframe there. If there’s no Source Text keyframe, the expression looks for a marker and will increment a value by 1 for each marker. NB. I recognize that expressions have no memory, but I have a further expression in my back pocket that returns the number of words for each Source Text keyframe. So I wonder if there’s a way to use the running marker Index number and subtract a derived value from the ‘word total’ if necessary? NB. If necessary (via Sonix) I can additionally produce a .srt file that has the timecode for every word).
Thank you for your time ladies and gentlemen.